I think the reason I’m obsessed with CLIP is because it’s hard evidence for unified meme theory.
Unified meme theory states that the “meme” - defined as the transmissible unit of human thought, and defined as a picture with some words on it that gets copied on the internet - are not different.
A meme is picture+words because it represents a gradient in semantic space.
Semantic space is a much-theorized “embedding” for language concepts. Like if you think about a chair, and then you think about a chaise, and then you think about a silla… there’s a region in semantic space that activates from all of those, in your mind and mine.
The image provides a field, an area in semantic space. The words provide a vector. Your attention moves to that area of semantic space, and then updates in the direction that the vector points - a gradient in semantic space.
Depending on how far the words send you, and how well developed your map of that semantic space is, either it lands or it doesn’t. If it works on you, you save it to send it to someone else later.
Showed this one to my gf. She made me send it to her so she can send it to her dad:

But it has to be the right person: you have to simulate their whole mental state to understand whether this gradient will work on them. So memes follow social topologies as well.
This makes sense, though: semantic space is a product of social animals using mimetic calls.
CLIP encodes visual image and text about that image into the same embedding space. You’ve probably seen this image, maybe with a caption that says “AI is too dumb to tell the difference between an apple and an iPod lol”:
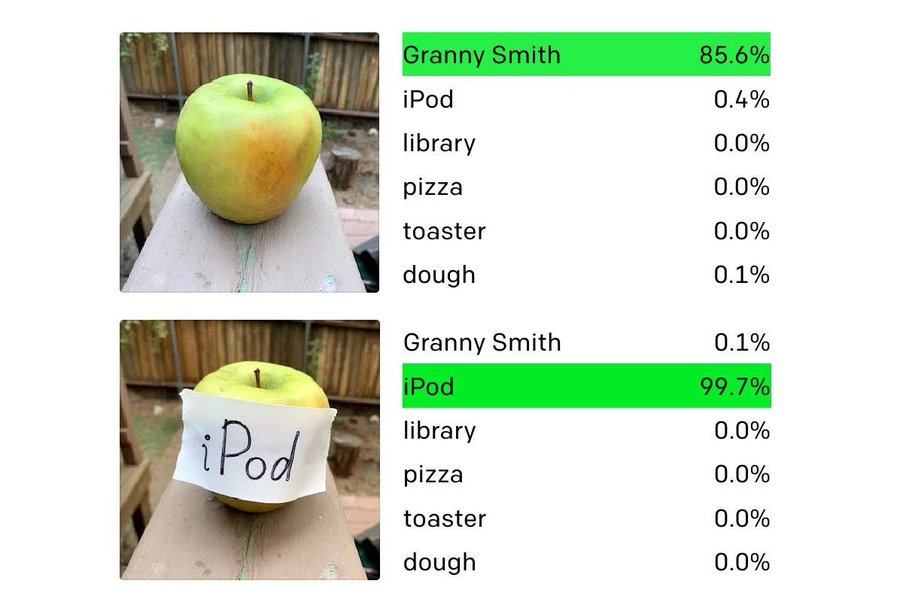
But this is actually amazing!
This neural net learned to read. It learned to read handwriting! It’s not very good at it, but it wasn’t trained to do that. It was trained to match flashcards of images to text captions.
Is this not mostly a picture that says “iPod”? With a hint of apple and a dash of wood fence?
The fact that CLIP can recognize letters in photographs is a sign that they’re encoded in the brain the same way as other visual data. They’re just a bunch of weird squiggles, but they cause the meaning of the image to change.
In predictable ways!
There’s a high-dimensional space representing all these concepts and how they interact.
Your brain evolved to think about how other monkeys think about other other monkeys. CLIP is trained on a contrastive pretraining objective. We are kinda the same.
You can subtract the “appleness” from an image. Or you can move along an axis that has fixed appleness but change in iPod. CLIP has a 512-dimensional space and the neurons have been shown to be multimodal so there are more “axes” than that.
This is a great thread showing how CLIP vectors encode world knowledge and how you can add and subtract them:
[https://x.com/haltakov/status/1367950896177569808](https://x.com/haltakov/status/1367950896177569808
 )
)
If you feel like you came up with these ideas independently, that’s probably true! We’re literally studying our own minds here.
Incidentally, this is why CLIP is perfect for meme search. I’d been wanting to make this program for a long time, but until now there wasn’t a way to search for concepts embedded in both text and visual data. Now there is: memery
I thought I was going to have to combine a bunch of things - OCR the text, object recognition on the images, combine a bunch of metadata and manual tags to make a classifier or something. But with CLIP it “just works” 😘
Unified meme theory draws on this paper, “Embodiment vs. Memetics,” by Joanna Bryson. She says humans have a special combination of temporal imitation and second-order thinking that creates semantic space fertile for memetic vectors.

Temporal imitation: like birds, we have the ability to repeat short, ordered phrases of sound. Birds do their little mating calls and dances, humans do too.
Most types of creatures don’t do this call and response. So they don’t have imitatable units of action.
Second-order thinking: our heritage as troop primates means we think not only about the internal state of our fellows, but about their internal models of our state! Or even of third parties.
This creates a hall of mirrors effect. You can go fractally in any direction.
The hall of mirrors is filled with the imitatable units of action, in all of their infinite slight variations.
It’s a holographic construct, a multi-dimensional space intersecting with a smaller dimensional reality. That’s semantic space. You can move through it with your mind.
Memes don’t have to be image macros. They could be visual, behavioral, sounds, motions. TikTok dances are memes. Dabbing. Imitatable, variational units of action.
What used to be “image macros” became the most common definition for “memes” though, because they are so easily shared. Humans are visual creatures. We can parse an image instantaneously, and words almost as fast. And early internet could share them faster than video.
Now that video is cheap and fast to share, you can have all these other types of visual/behavioral memes on TikTok (riding a skateboard + drinking cranberry juice + Fleetwood Mac * your_creative_addition_here).
But it still takes time to parse them, vs a screenshot or a meme.
This is why viral TikToks use overlaid captions, btw. It’s a memetic grappling hook that grabs you and reels you into their region of memespace where you will then enjoy the video.
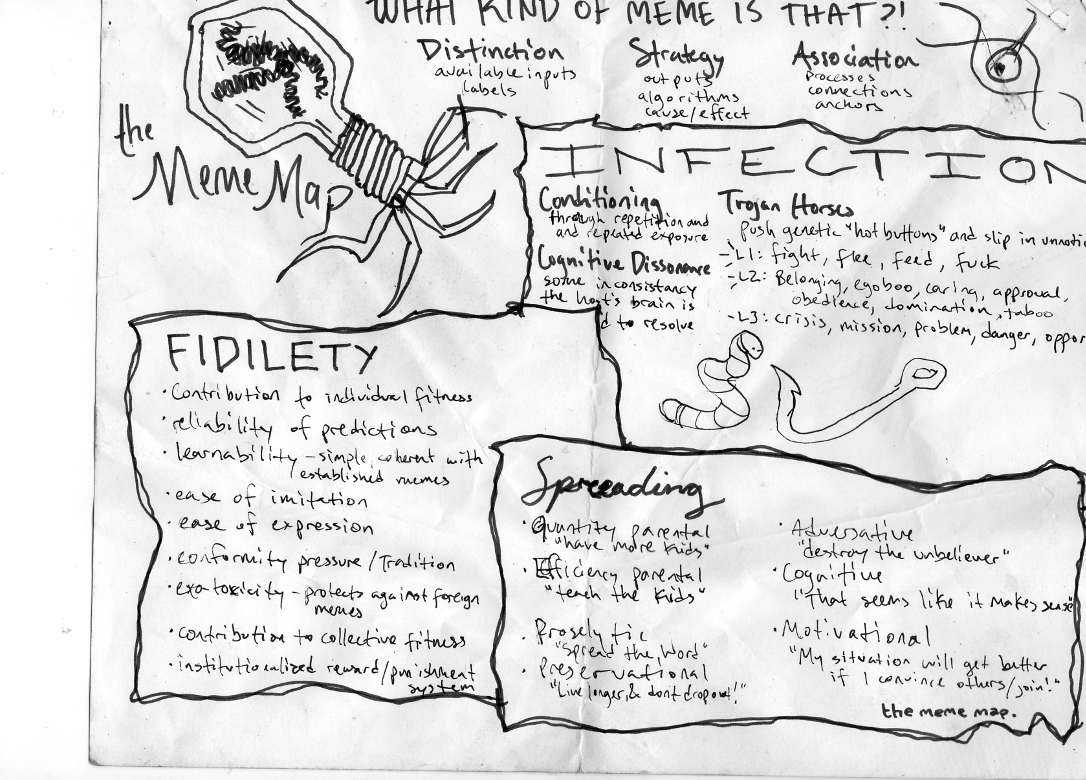
Have to go back to selling prepackaged memes instead of theorizing about them. I’ll leave you with this diagram I made circa 2013:
Original thread:
I think the reason I'm obsessed with CLIP is because it's hard evidence for unified meme theory
— 🎭 (@deepfates) May 25, 2021