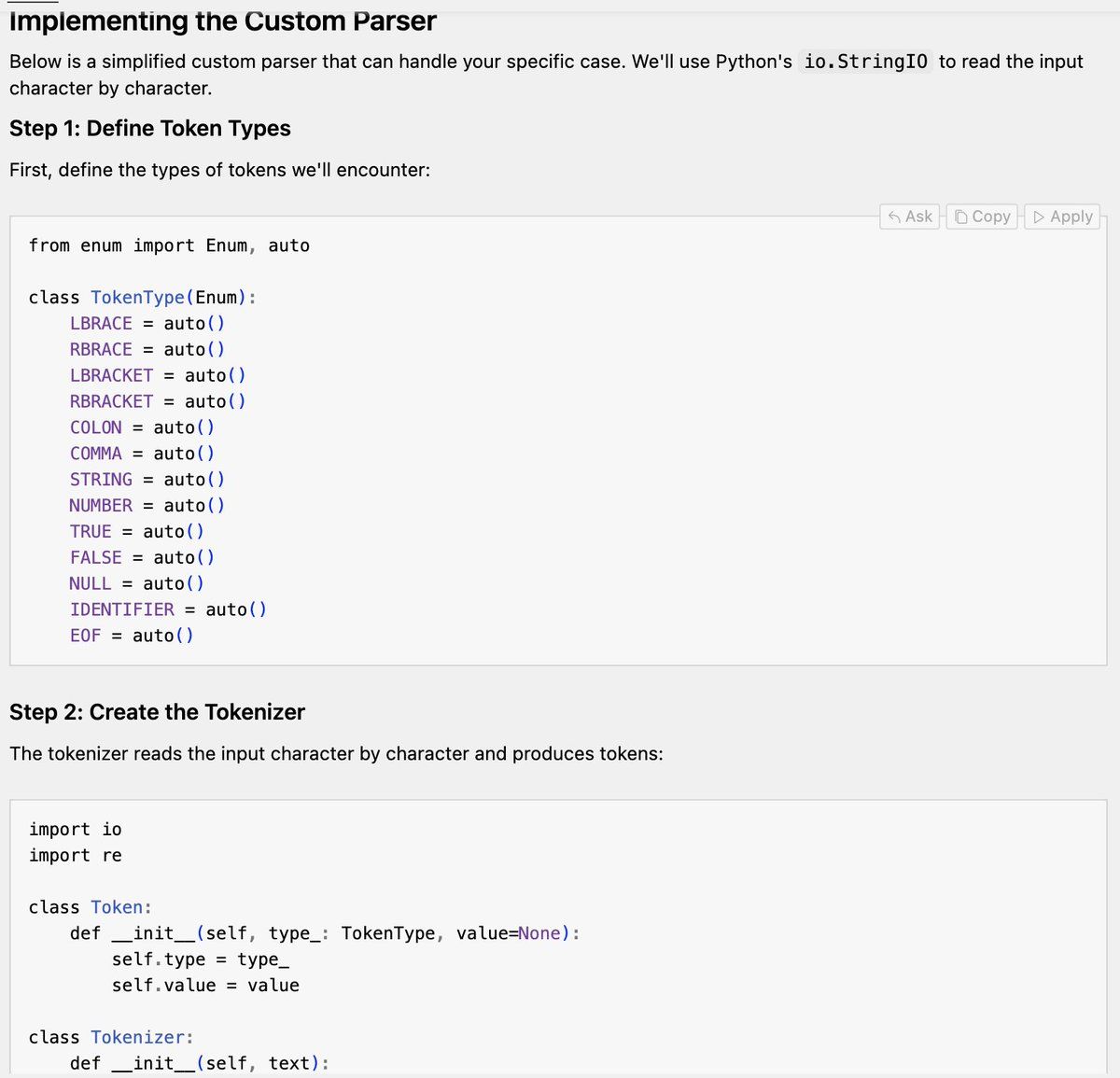
 |||
|||
I wrote a Python script to convert your Twitter archive into a training dataset for fine-tuning a language model on your personality. It also extracts all your tweets, threads, and media into markdown files so you can read them or easily make a website. (Link in next tweet)
@deepfates what's the fastest way for me to build a clone of myself like yours? Is there a repo where I can just point it at my text and get a thing I can self host (so I can do this experiment of my older self talks to my young self)
— Defender (@DefenderOfBasic) November 17, 2024
Just download this file and run it on your Twitter archive with Python. It has no dependencies, so you don’t even need to worry about Python environment stuff. https://gist.github.com/deepfates/78c9515ec2c2f263d6a65a19dd10162d
It’s not perfect. The biggest problem right now is that your “note tweets” (the internal name for Long Tweets) are not included. That’s because the archive format is janky and bad, sorry. There’s a different structure for the note tweet file. 🤷 https://www.theverge.com/23453703/twitter-archive-download-how-to-tweets
This could be fixed by using an actual JavaScript parser in Python, or writing your own. o1-preview wrote one for me but it made the file like twice as long, so I decided to drop it. Honestly, could probably rewrite the whole thing in JS and have a better time of it.
The fine-tuning data includes all your posts and threads. It concatenates threads into longer texts, so your clone should be able to make multi-thought responses. It also includes the text of posts you replied to, if you hit the ♥️ button on them.
This is because the archive saves the text of all your liked posts. Another W for tpot social norms! So for your replies, if we can get the text of the post you replied to, we make that the “user” role and your reply the “assistant” role.
It’s a really simple, blunt instrument right now, but it works. I used this on my own archive to create the AI behind http://deeperfates.com and used similar logic on the glowfic Project Lawful to create the Infinite Keltham Machine. It could definitely use improvement!
Things you could do to make this better:
That last one is because liked-tweets don’t have parent IDs, so all the like-reply pairs are separate units right now.
Another thing I’d like to do at some point: cluster the tweets and label the clusters with an LLM. Then we could do some automatic data improvements like in this excellent post by https://snats.xyz/pages/articles/breaking_some_laws.html
If you don’t even want to fine-tune a model, that’s fine too - just do --output-formats markdown and you’ll get a folder of text and media files. Threads get one file each, everything else is collected by day. You can explore it like any other vault.
Make your archive into a website with any of the site generators that take markdown files. Or, if you don’t want to write any code at all, just use http://blot.im! It’s $4/month and makes a website out of a folder. Not an ad, I just like their service and use it myself.
Good question! This currently just outputs the OpenAI format, because that’s what uses. I like OpenPipe because you can continuously collect the logs and add them to your dataset. Check next tweet for a script to convert to ShareGPT.
this will be useful — does it use sharegpt format?
— interstellarninja (@intrstllrninja) November 17, 2024
Here’s the script. Just scrapped it out of a larger codebase so it’s not very refined, but it should work. Run it like python convert_oai_to_sharegpt.py conversations_oai.jsonl conversations_sharegpt.jsonl https://gist.github.com/deepfates/d152924514b2099d132a203100dfeb24
