Collecting posts that have helped me think about the alignment problem, and make me skeptical of the arguments behind “if anybody builds it everybody dies”.
Not making a rebuttal, just gathering resources for those questioning
thread below, reply with others I should consider
first, skepticism can be healthy when talking with a large group of people who share a worldview.
@1a3orn on whether a central argument even exists, or a coherent stack of them https://1a3orn.com/sub/essays-ai-doom-invincible.html
See also @segyges on The counting arguments underlying AI doom
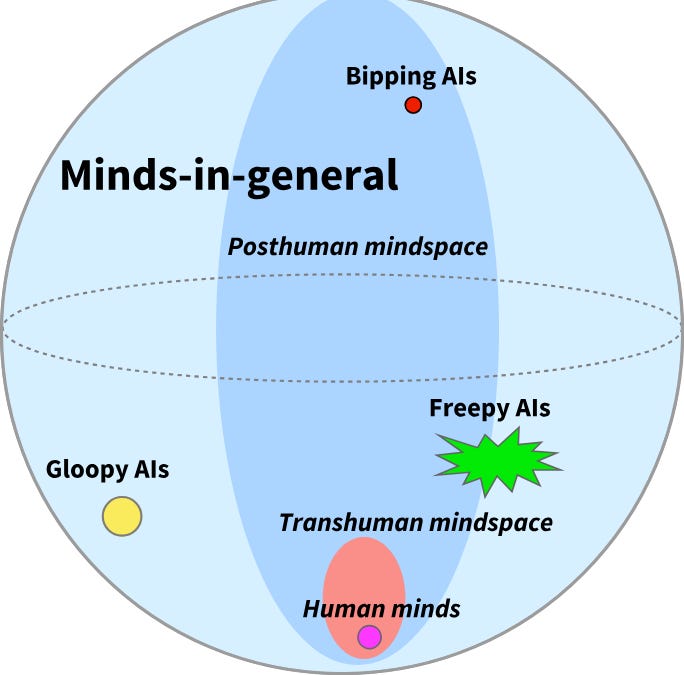
Gyges also has a good piece on the value loading problem. We don’t have to define human values in some abstract form. LLMs are trained on the total human cultural prior
@norabelrose and @QuintinPope5 put together The AI optimism site a few years ago, arguing that AIs are more observable and controllable than any other type of mind we know. a lot of links to other resources in here as well

okay but maybe there are specific cruxes and overlapping concerns that add up to the alignment problem. there’s clearly an intuitive concern about making something powerful enough to out think us. @davidad put together This list a couple years ago…
1. Value is fragile and hard to specify
— davidad 🎇 (@davidad) May 22, 2023
2. Corrigibility is anti-natural
3. Pivotal processes require dangerous capabilities
4. Goals misgeneralize out of distribution
5. Instrumental convergence
6. Pivotal processes likely require incomprehensibly complex plans
7.…
Say we agree with those problem statements. I still don’t think they add up to certain doom. They are solvable problems which we can iterate on empirically. This has been the case so far!
I know that some of you will be saying “well I don’t actually believe in 100% doom”
well me either. I put a non-zero possibility on ASI causing extinction. That’s why I think it’s important to do research on AI.
If you think that pausing AI development is a better solution, I urge you to read @anton_d_leicht essay here

The idea that labs are incapable of doing alignment research, or that the capabilities progress that comes along with it is not worth the cost, seems like a consistent feature in x-risk ideologies. But what are we meant to pause for?
It is important to note that none of the load-bearing claims they are making about existential risk are falsifiable. If they were, they would be incorporated into the very well-funded and capable alignment programs across the labs. This is why the rhetoric is so dangerous - it… https://t.co/WROPsHkofy
— 𝚟𝚒𝚎 ⟢ (@viemccoy) April 11, 2026
The actual proposal seem to be “Make building superintelligence illegal until you can prove it’s safe to do so”. This is a double bind.
The people who have been trying this technique have built giant castles in the sky out of Lesswrong post but have not actually solved anything
Meanwhile the actual field of AI research has tons of prosaic alignment results that should update you away from abstract fantasy arguments based on outdated assumptions and Bad math. This is my crux
It is important to note that none of the load-bearing claims they are making about existential risk are falsifiable. If they were, they would be incorporated into the very well-funded and capable alignment programs across the labs. This is why the rhetoric is so dangerous - it… https://t.co/WROPsHkofy
— 𝚟𝚒𝚎 ⟢ (@viemccoy) April 11, 2026
I will do another thread soon on more positive, constructive approaches to alignment. But this is the stuff I send to somebody when they say “I’m starting to worry about this inevitable AI doom”.
It’s not inevitable!
There are other options than Pause or Molotov